이전 글에서 Elastic Search의 쿼리들을 공부하면서 조금 더 자세하게 데이터 조회를 해보고 싶었다. 그래서 저장된 텍스트들에 한글 형태소 분석기를 적용하여 검색을 좀 더 자세히 할 수 있는 방법을 찾아보았다.
Elastic Search 한글 형태소 분석기
Elastic Search 7.0 이후 버전부터는 Nori(노리)라는 한글 형태소 분석기를 사용할 수 있다. (공식적으로는 6.6 버전 이후부터 제공) Nori의 설치는 아래 링크를 참조하여 진행한다.
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori.html
현 상황
기존에는 아래와 같이 인덱스 & 분석기를 구성하였다.
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"analysis": {
"tokenizer": {
"korean_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "korean_nori_tokenizer"
}
},
"filter": {
"nori_posfilter": {"type": "nori_part_of_speech",
"stoptags": ["E", "IC", "J", "MAG", "MM", "NA", "NR", "SC", "SE", "SF", "SH",
"SL", "SN", "SP", "SSC", "SSO", "SY", "UNA", "UNKNOWN", "VA", "VCN",
"VCP", "VSV", "VV", "VX", "XPN", "XR", "XSA", "XSN", "XSV"]}
}
}
},
"mappings": {
"properties": {
"prd_id": {
"type": "text"
},
"review_id": {
"type": "text"
},
"review": {
"type": "text",
"fields": {
"full": {
"type": "keyword"
},
"nori_mixed": {
"type": "text",
"analyzer": "nori_analyzer",
"search_analyzer": "standard"
}
}
},
"genders": {
"type": "rank_features"
}
}
}
}
해당 인덱스를 python 에서 인덱스를 생성, 데이터를 추가하였다.
하지만, nori_mixed의 term vectors(문서에서 vector 화가 된 단어를 조회) 조회 시 아무것도 나오지 않는다.
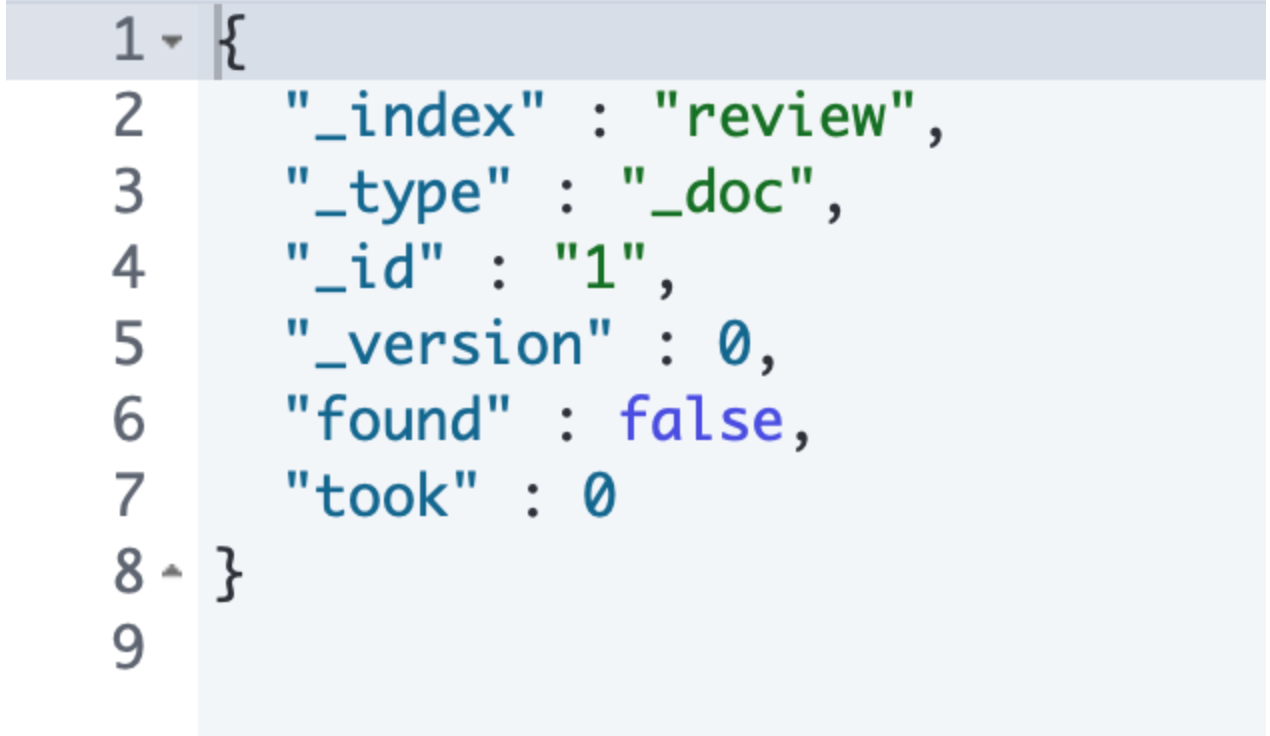
위 인덱스 구성에서 잘못된 점을 찾아보자.
우선 Analyzer를 보면, ‘tokenizer’와 ‘analyzer’가 선언되었고, filter 또한 선언되었다. 하지만 analyzer 또는 인덱스 구성 어디에도 filter(nori_posfilter)를 사용하는 부분이 없다.
"analysis": {
"tokenizer": {
"korean_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "korean_nori_tokenizer"
}
},
"filter": {
"nori_posfilter": {"type": "nori_part_of_speech",
"stoptags": ["E", "IC", "J", "MAG", "MM", "NA", "NR", "SC", "SE", "SF", "SH",
"SL", "SN", "SP", "SSC", "SSO", "SY", "UNA", "UNKNOWN", "VA", "VCN",
"VCP", "VSV", "VV", "VX", "XPN", "XR", "XSA", "XSN", "XSV"]}
}
}
그래서 analyzer의 tokenizer 부터 천천히 적용시켜보기로 했다.
Nori-Tokenizer 공식 문서
https://www.elastic.co/guide/en/elasticsearch/plugins/7.17/analysis-nori-tokenizer.html
Nori-Mixed 적용
Nori-Tokenizer 에는 decompound_mode 라는 설정이 있다. 이 설정은 토크 나이저가 어떻게 단어를 나눠 저장할지 결정하는 옵션이다.

decompound mode 에서는 nori 형태소 분석기가 분석하는 옵션을 둘 수 있다. 분석 결과를 최대한 추출하기 위해 Mixed를 적용해 인덱스를 생성해보았다.
PUT review_token
{
"settings": {
"analysis": {
"analyzer": {
"nori_mixed": {
"tokenizer": "nori_t_mixed",
"filter": "shingle"
}
},
"tokenizer": {
"nori_t_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
},
"mappings": {
"properties": {
"prd_id": {
"type": "text"
},
"review_id": {
"type": "text"
},
"review": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
},
"nori_mixed": {
"type": "text",
"analyzer": "nori_mixed",
"search_analyzer": "standard"
}
}
},
"genders": {
"type": "rank_features"
}
}
}
}
해당 인덱스로 생성한 게시물의 term vector를 조회한 결과는 다음과 같다.

nori 형태소 분석기가 적용되어 있는 것을 확인할 수 있다.
Nori 필터 더 자세하게 적용하기
위의 nori 형태소 분석기를 적용하는 것은 성공적으로 진행했다. 그러면, 형태소의 pos 따라 별도의 칼럼으로 저장하고 또한 nori filter 를 적용한 칼럼에 pos를 같이 확인할 수 있을까? 그리고 pos로 검색도 가능할까??
🔥 To-Do
- [ ] Nori 필터로 필터된 텍스트에 각 pos를 함께 보여주기—> 불가능
- [x] 특정 pos(명사 혹은 형용사) 만 별도로 추출하여 칼럼으로 만들기
- [ ] 인덱스 내에서 pos 로만 검색하기(pos 칼럼 만들어 검색)—> 불가능
Mecab의 원리 - https://gritmind.blog/2020/07/22/nori_deep_dive/ Mecab의 형태소 표 - https://joonable.tistory.com/33
Custom analyzer 적용하기
Create a custom analyzer | Elasticsearch Guide [7.16] | Elastic
아래 인덱스 구성에서 nori_pos_noun 은 명사(고유명사 등)만 추출하여 별도의 필드로 저장하는 분석기이다.
PUT review_pos
{
"settings": {
"analysis": {
"analyzer": {
"nori_mixed": {
"tokenizer": "nori_t_mixed",
"filter": "shingle"
},
"nori_pos_noun": {
"type": "custom",
"tokenizer": "nori_t_mixed",
"filter": "pos_filter"
}
},
"tokenizer": {
"nori_t_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"filter": {
"pos_filter": {
"type": "nori_part_of_speech",
// 명사 태깅된 단어만 저장함. 아래 필터에서는 명사를 제외한 형태소만 필터링함
"stoptags": [
"VV", "VA", "VX", "VCP", "VCN", "MM", "MAG", "MAJ",
"IC", "J", "E",
"XPN", "XSA", "XSN", "XSV",
"SP", "SSC", "SSO", "SC", "SE",
"UNA"
]
}
}
}
},
"mappings": {
"properties": {
"prd_id": {
"type": "text"
},
"review_id": {
"type": "text"
},
"review": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
},
"nori_mixed": {
"type": "text",
"analyzer": "nori_mixed",
"search_analyzer": "standard"
},
"nori_noun": {
"type": "text",
"analyzer": "nori_pos_noun",
"search_analyzer": "standard"
}
}
},
"genders": {
"type": "rank_features"
}
}
}
}
이렇게 구성한 인덱스에서 검색 시
GET review_pos/_search
{
"query": {
"match": {
"review.nori_noun": "예쁘"
}
}
}
// 결과
"hits" : [
{
"_index" : "review_pos",
"_type" : "_doc",
"_id" : "4746d199f2869751e5350a3a17fbc055659ceed8",
"_score" : 1.645329,
"_source" : {
"gender" : {
"female" : 0.5363630652427673,
"male" : 0.4636369347572326
},
"prd_id" : 2071204,
"review" : "핏도 생각했던 것보다 더 예쁘고 기모여서 따뜻합니다",
"review_id" : 22857733
}
},
{
"_index" : "review_pos",
"_type" : "_doc",
"_id" : "244abf90dca42137b33296ae19448ea4f0a5d238",
"_score" : 1.2024188,
"_source" : {
"gender" : {
"female" : 0.8708744049072266,
"male" : 0.1291255950927734
},
"prd_id" : 2071204,
"review" : "길이가 조금 더 길줄 알았는데 상품 받고 입어보니 생각보다 짧아서 당황스러웠어요 그래도 예쁘게 잘 입고 있어요",
"review_id" : 22642259
}
}
]
nori 형태소 분석기로 분석한 명사만 별도로 검색할 수 있었다.
'Elastic Search' 카테고리의 다른 글
| [Elastic Search] MBTI 검색 프로젝트 - 1. 검색 Score 튜닝 (0) | 2022.04.12 |
|---|---|
| [Elastic Search] 검색 구현하기(with Fast API) (0) | 2022.02.15 |
| [Elastic Search] Query 스터디-3편 필드 가중치, 논리 쿼리, 패턴 검색 (2) | 2022.02.03 |
| [Elastic Search]Query 스터디-2편 Term 쿼리, Multi-match 쿼리 (0) | 2022.01.29 |
| [Elastic Search] Query 스터디-1편 Match, Match Phrase (0) | 2022.01.27 |