기존 콘텐츠에서 이모티콘만 파싱 하여 데이터를 RDB에 수집하였습니다.
(ES Analyzer에 regex filter를 적용하여 분석하는 것은 다음에 진행해보겠습니다!)
스키마를 다음과 같이 구성하고 데이터를 Insert 하였습니다(RDB)
T: t_emoji_dashboard
Columns: emoji, mbti_type(MBTI 타입 입니다), emoji_count(각 문서별 등장 횟수입니다)
SELECT emoji, mbti_type, sum(emoji_count)
FROM t_emoji_dashboard
WHERE emoji = '😘'
GROUP BY emoji, mbti_type
ORDER BY mbti_type, sum DESC
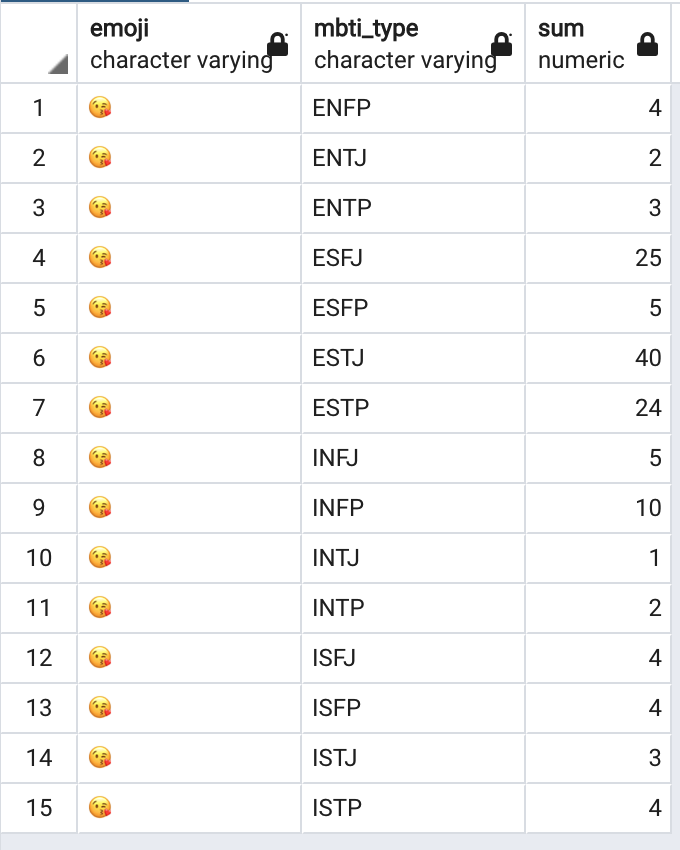
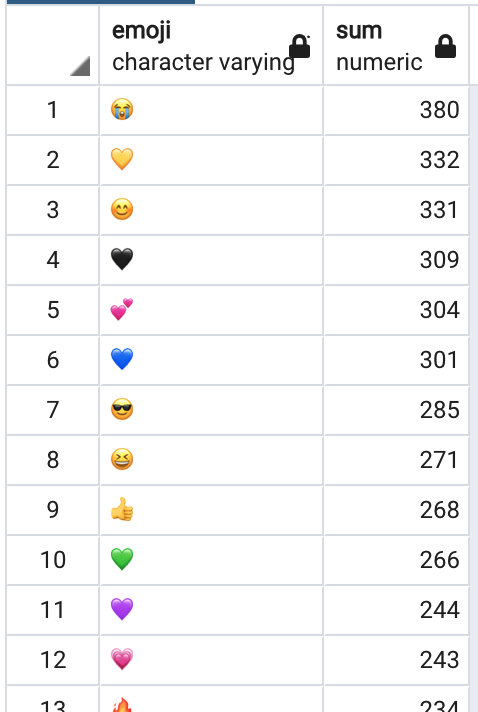
사용한 쿼리로 조회한 결과입니다. (특정 이모티콘만 조회하였습니다), 오른쪽은 테이블 전체 데이터를 조회하였습니다.(Group by emoji)
RDB로 우선 저장하여 현재 문서에 포함된 이모티콘을 파악하였습니다.
위와 같이 RDS 쿼리처럼 ElasticSearch에서 조회를 진행해보겠습니다.
GET mbti/_search
{
"size": "0",
"query": {
"terms": {
"contents": ["😘"]
}
},
"aggregations": {
"significant_mbti_type": {
"significant_terms": {
"field": "keyword" ,
"min_doc_count": 0
}
}
}
}
실행 결과를 다음과 같습니다.
{
"aggregations" : {
"significant_mbti_type" : {
"doc_count" : 136,
"bg_count" : 27146,
"buckets" : [
{
"key" : "ESTJ",
"doc_count" : 40,
"score" : 0.28670597307320017,
"bg_count" : 4043
},
{
"key" : "ESTP",
"doc_count" : 24,
"score" : 0.12469690824841013,
"bg_count" : 2807
},
{
"key" : "ESFJ",
"doc_count" : 25,
"score" : 0.11545638190983143,
"bg_count" : 3065
},
{
"key" : "ESFP",
"doc_count" : 5,
"score" : 0.007764077040010751,
"bg_count" : 824
}
]
}
}
}
위 쿼리에서 contents는 text 필드이자, tokenized 된 필드입니다. 그래서 term 쿼리 작동이 되었습니다!
Significant terms aggregation | Elasticsearch Guide [8.1] | Elastic
Show significant_terms in contextFree-text significant_terms are much more easily understood when viewed in context. Take the results of significant_terms suggestions from a free-text field and use them in a terms query on the same field with a highlight c
www.elastic.co
쿼리를 설명하자면, contents 필드 내에서 해당 이모티콘을 포함한 게시물을 가져옵니다.
그리고 문서의 수를 종합해서 보여줍니다( doc count Sum )
이를 보면 직접 데이터를 파싱 해서 넣은 RDB와 수치가 비슷한 것을 확인할 수 있습니다.
다음 포스팅에서는 ES Analyzer에 Regex filter를 사용하여 콘텐츠 내 이모티콘만 저장하는 필드를 만들고
1) 문서 내 저장된 이모티콘 수
2) 각 이모티콘 사용별 MBTI 타입
등을 조회해보겠습니다!
'Elastic Search' 카테고리의 다른 글
| [Elastic Search] MBTI 검색 프로젝트 - 3. API 구축하기 (0) | 2022.04.29 |
|---|---|
| [Elastic Search] MBTI 검색 프로젝트 - 2. Emoji 검색 및 Aggregation(3편) (0) | 2022.04.24 |
| [Elastic Search] MBTI 검색 프로젝트 - 2. Emoji 검색 및 Aggregation (0) | 2022.04.13 |
| [Elastic Search] MBTI 검색 프로젝트 - 1. 검색 Score 튜닝 (0) | 2022.04.12 |
| [Elastic Search] 검색 구현하기(with Fast API) (0) | 2022.02.15 |

